
Generative artificial intelligence has emerged as a cornerstone of innovation and the automation of business operations. The decade’s most hyped technology employs computational methods to generate novel, creative outputs, typically in response to conversational prompts or inputs.
It possesses the capability to respond to queries, scrutinize data, compose code, conceive images from textual descriptions, or generate videos portraying real or even completely imagined scenarios.
Globally, organizations have, since the release of ChatGPT by OpenAI last fall, reimagined everything from the creation of new products, marketing, content creation, automation, and decision-making to enhancing productivity.
However, the same organizations are, from such an early stage, being confronted by apprehensions regarding the security and privacy of their data and intellectual property.
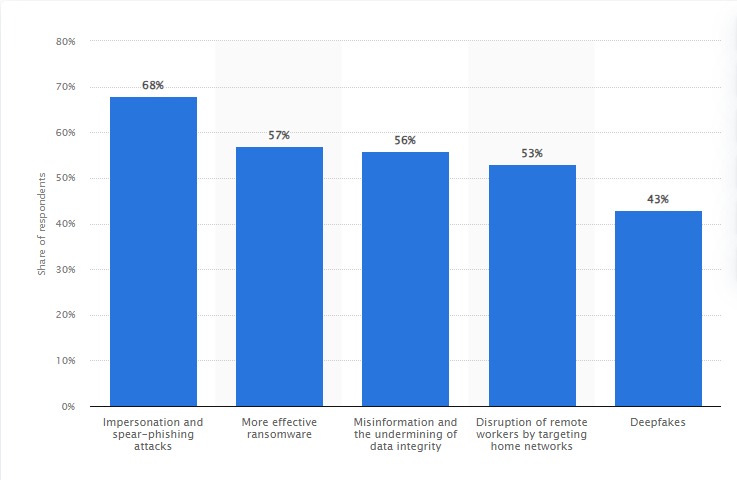
While the knee-jerk reaction would be to tap into existing solutions, the risks far outweigh their effectiveness.
The Generative AI’s Enterprise IP Threat Intensifies
As TechCrunch reports, many enterprises are taking a cautious approach to the technology that continues to take on the world by storm.
Overt security and privacy risks, paired with a reluctance to depend on superficial, temporary fixes, have compelled numerous firms to outrightly prohibit the use of these tools.
ChatGPT and similar generative AI platforms amass training data from millions, if not billions, of words and images on the internet. Some of this content falls within the public domain, while other parts are licensed.
However, a significant portion of the content that generative AI utilizes for training doesn’t fall into either category.
In a recent news article, Bloomberg highlighted an incident where Getty Images, a leading provider of licensable visual content, initiated legal proceedings against two prominent firms that offer generative AI tools.
According to IEEE Spectrum, “Patent law and copyright law were crafted by humans, for humans. Intellectual-property law, as the world understands it, explicitly doesn’t recognize nonhuman creators.”
Some organizations, instead of using ready generative AI software like ChatGPT, are training in-house large language models (LLMs). This method ensures that the personal assistants, otherwise called agents, learn from relevant data sets to provide the desired output for enhancing workflow and productivity.
While leveraging in-house data might seem like an answer, the legalities surrounding copyrights and intellectual property remain a mystery to many.
Unresolved questions concerning the rights to the data, the model itself, and the output it generates continues to loom, with no clear-cut answers to support the necessary decision-making.
AI Privacy Breaches On the Rise
Governments around the world, but mainly in the US and Europe, are working on legal frameworks to provide oversight of the artificial intelligence industry.
Matt Hervey, an IP partner and Head of Artificial Intelligence Law, in an interview with Lexology “on the implications for IP of the new draft of the EU AI Act,” said that the bill aspires to illuminate the intersection of generative AI and copyright infringement, mandating providers of generative AI to publicly disclose specifics of copyrighted works utilized in training.
However, organizations are left with no alternative but to initiate protective measures for their LLMs’ training data and, indeed, for the generative AI tools they construct.
Given that, according to Gartner, 41% of firms have disclosed a privacy infraction or a correlated security incident, the need to safeguard corporate intellectual property has become more crucial than ever.
Intriguingly, half of the incidents Gartner referred to emanated from internal data compromises, which implies that the threat posed by generative AI runs deeper than many organizations can comprehend.
The TechCrunch report, while exploring the extent of these security threats to enterprise IP, found that workers in these AI-focused organizations are progressively inputting classified business documents, customer data, source code, and other pieces of regulated information into LLMs, posing a substantial risk.
The real danger starts to thaw with LLMs being trained on relatively new data sets that indirectly compromise intellectual property – a situation that would come to light in the event of a data breach.
A compromised model means that the organization is at a greater risk of losing its intellectual property through contracts and other legal obligations.
That’s not all; generative AI models are at risk of automated hacking and cyber-attacks, further increasing the risks of enterprise IP making it into the hands of competitors who may duplicate, leak or steal the data.
New Security Foundation
Organizations need to keep up with the ever-changing regulatory environment as governments race to provide much-needed oversight. Businesses must ensure that they are responsible for the data entrusted to them and stay abreast with regulatory requirements.
Crucially, the threat posed by generative AI to corporate intellectual property necessitates a fresh perspective on security, as it has become inadequate to merely encrypt fields in databases.
Exploring Confidential Computing
Organizations that prioritize generative AI model protection will avoid falling into the glaring trap of data breaches, both internally and externally. Furthermore, they are going to comply with regulatory requirements as the law stipulates now but, most importantly, in the future.
This brings us to “confidential computing.” The phrase refers to a recently developed data security strategy safeguarding data in use while ensuring code authenticity.
Confidential computing presents a solution to the intricate and pressing security challenges associated with large language models (LLMs) like ChatGPT.
It stands ready to enable enterprises to fully harness the immense capabilities of generative AI without forfeiting their security needs.
Under the new framework of confidential computing, data, and intellectual property are securely isolated from infrastructure operators and made accessible solely to verified applications operating on trustworthy CPUs.
Throughout the execution process, data privacy is preserved via encryption.
Cloud service providers like Azure, AWS, and GCP, including chip makers like Nvidia, have been paying a lot of attention to confidential computing. It ensures that even in the face of a malicious cyberattack—infrastructure data, IP, and code remain protected and unreachable.
Experts believe confidential computing is the final missing piece to the puzzle that must be solved for generative AI to take off.
Related Articles
- 11 Best AI Text Generators in 2023
- Reports Say Airbnb Revenue ‘Down By 50 Percent’ But the Company Says Number of Active Listings is Actually Rising
- New Twitter CEO Yaccarino is Desperately Fighting to Bring Brands Back With ‘Hand-to-Hand Combat’
What's the Best Crypto to Buy Now?
- B2C Listed the Top Rated Cryptocurrencies for 2023
- Get Early Access to Presales & Private Sales
- KYC Verified & Audited, Public Teams
- Most Voted for Tokens on CoinSniper
- Upcoming Listings on Exchanges, NFT Drops