
Amazon’s Artificial General Intelligence (AGI) team recently unveiled this week a groundbreaking new text-to-speech (TTS) model called BASE TTS that promises to take synthetic speech generation to unprecedented new heights. Trained on 100,000 hours of speech data across multiple languages, BASE TTS flaunts nearly 1 billion parameters, making it the largest TTS model created so far.
But it’s not just about size. In developing BASE TTS, Amazon aimed to create a model that displays emergent abilities, allowing it to intuitively handle complex linguistic features well beyond the training data. Essentially, the researchers claim that the model can do things it wasn’t explicitly programmed to do. If these abilities are truly emergent, it could be one of the biggest discoveries in AI so far.
Early analysis suggests that BASE TTS has crossed an inflection point, enabling new levels of versatility, expressiveness, and contextual awareness and may just be a major stepping stone towards sentient AGI.
Are Large Language Models Really “AI”?
Over the past few years, LLMs like OpenAI’s GPT-4 0r Google’s Gemini have sparked renewed excitement around artificial intelligence by showcasing new abilities to generate remarkably human-like text.
However, LLMs are not true AI systems that can result in the creation of general intelligence or the development of sentience (as far as we know). Rather, they are extremely complex pattern recognition algorithms that use a gargantuan amount of textual data, allowing them to make highly accurate predictions about upcoming words and sentences. It’s closer to your phone’s text prediction suggestions than it is to a true AGI like HAL 9000 or Skynet.
That said, researchers noticed that LLMs seem to reach far more advanced stages of development than initially predicted after reaching a certain scale, suddenly displaying versatile competencies like summarization and translation despite no explicit training. Dubbed emergent abilities, such behaviors arise indirectly from the model’s underlying statistical representations.
In developing BASE TTS, Amazon (AMZN) hypothesized that scaling up a TTS model on ample speech data could elicit similar emergent abilities, boosting prosody (patterns of sound in speech and poetry), emotion, and pronunciation accuracy as complexity grows.
Deconstructing BASE TTS: Model Architecture and Training Process
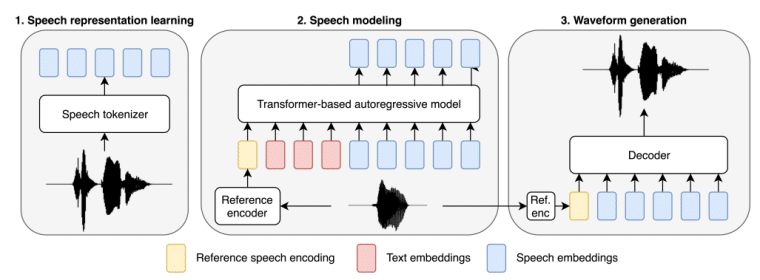
BASE TTS incorporates several innovations that enable unprecedented scalability. Fundamentally, it approaches TTS by predicting discrete speech representations rather than waveforms. Specifically, it leverages a novel speech discretization technique to convert raw audio into compressed “speechcodes” retaining key acoustic properties.
This strategy draws inspiration from the way LLMs handle text as discrete tokens. By operating directly on speechcodes, BASE TTS sidesteps waveform synthesis complications. The streamable speechcodes also facilitate efficient, real-time audio generation capabilities.
The model itself resembles a standard Transformer-based LLM. During training, BASE TTS ingests text paired with target speechcodes, honing its ability to map input language to corresponding speech representations.
A separate lightweight decoder then reconstructs high-fidelity, natural waveforms from the model’s predicted speechcodes. This modular setup eased model scaling while preserving audio quality.
Emergent Abilities: Real Progress or Just Hype?
So, does BASE TTS truly showcase enhanced comprehension and context handling? The researchers assessed model variants using an “emergent abilities” benchmark spanning complex semantic and syntactic phenomena like irony, foreign words, unusual punctuation, nested clauses, and more.
Also read: Meta Delays Its AI-Speech Generator, Acknowledging That It’s a Great Tool For Scammers
They found that medium and larger-sized versions of BASE TTS clearly outperformed the smaller counterparts, appropriately conveying challenging inputs involving compound nouns, emotions, whispers, code-switching, and confusing sentences. The gap was substantial enough to indicate emergent linguistic aptitude resulting from scaling up the model’s parameters.
Nonetheless, all models still fumbled in plenty of cases. Meanwhile, skeptics argue that the chosen evaluation set may play too strongly to BASE TTS’s strengths while downplaying its weaknesses. The reality likely rests somewhere in between. Either way, the capabilities displayed by the new model strongly suggest that TTS systems still have much room for growth.
Even if these abilities are “emergent,” that certainly doesn’t mean that this mash of code and data suddenly became sentient once it reached a certain size. It’s vaguely possible that this could work eventually, given that researchers have yet to find what actually induces sentience (or the illusion of sentience), but the chances seem low.
Practical Implications: New Era of Expressive, Versatile Speech Synthesis
No matter whether BASE TTS has any hint of AGI, it is still set to be a revolutionary AI model with far-reaching implicaitons. Most immediately, it could greatly boost the quality and naturalness of accessibility tools, screen readers, digital assistants, announcement systems, audiobook narrators, and more. Storytelling applications capable of conveying emotions through reading may also come into play.
However, perhaps more profound is the notion that speech technology seems to have reached a stage where scale and data access may result in rapid leaps in competence through emerging behaviors, much like the AI breakthroughs that catapulted LLMs into the limelight recently.
In that sense, BASE TTS could signal a new era where synthetic voices become flexible, vivid, and highly responsive conduits for information, creative expression, and human-machine communication. Their success rests on optimizing model architecture, speech representations, decoder efficiency, and training protocols – crucial areas for future TTS research.
Navigating the Ethical Implications of Expressive Speech Synthesis
The advent of versatile TTS models like BASE TTS that mimic voices and inflections is promising but also perilous from an ethical standpoint. While enhanced vocal interfaces can boost accessibility and creativity, the risk of misuse also grows exponentially.
After careful deliberation, Amazon decided against open-sourcing BASE TTS to prevent the model’s exploitation for perpetrating criminal activities like fraud, scams, impersonation, and misinformation campaigns. However, the company recognizes that inclusive and ethical innovations are crucial for social good.
Also read: Vatican’s AI Ethics Book: Guiding the AI Revolution
As such, Amazon established an internal review board to create guidelines for model development and deployment centered on transparency, accountability, bias detection, and minority protection. Researchers are quantifying data representation imbalances and developing algorithms to strengthen minority speech patterns.
The team also advocates for exploring techniques that allow voice cloning for benevolent personalization while inhibiting ill-intentioned vocal mimicry. They recommended external audits before launching any commercial offerings leveraging the capabilities showcased by BASE TTS.
Regarding commercialization, BASE TTS remains an experimental research endeavor for now without immediate plans for services integration. However, Amazon sees promise in responsibly enhancing vocal interfaces and will likely build on BASE TTS for future Alexa interactions and AWS speech offerings, pending rigorous reviews.