There’s no question that “data science” is becoming more and more popular. In fact, Booz Allen Hamilton (a consultancy) found:
The term Data Science appeared in the computer science literature throughout the 1960s-1980s. It was not until the late 1990s, however, that the field as we describe it here, began to emerge from the statistics and data mining communities. Data Science was first introduced as an independent discipline in 2001. Since that time, there have been countless articles advancing the discipline, culminating with Data Scientist being declared the sexiest job of the 21st century.
Unsurprisingly, there are countless graduate and undergraduate programs in data science (Harvard, Berkeley, Waterloo, etc.), but what is data science, exactly?
Given that the field is still in its proverbial infancy, there are a number of different perspectives. Booz Allen offers the following in their Field Guide to Data Science from 2015: “Describing Data Science is like trying to describe a sunset — it should be easy, but somehow capturing the words is impossible.”
Pithiness aside, there does seem to be consensus around some of the pertinent themes contained within data science. For instance, a key component is usually “Big Data” (both unstructured and structured data). Dovetailing with Big Data, “statistics” is often cited as an important component. In particular, an understanding of the science of statistics (hypothesis-testing, etc.), including the ability to manipulate data and almost always — the ability to turn that data into something that non-data scientists can understand (i.e. charts, graphs, etc.). The other big component is “programming.” Given the size of the datasets, Excel often isn’t the best option for interacting with the data. As a result, most data scientists need to have their programming skills up to snuff (often times in more than one language).
What’s a Data Scientist?
Now that we know the three major components of data science are statistics, programming, and data visualization, do you think you could identify data scientists from statisticians, programmers, or data visualization experts? It’s a trick question — they’re all data scientists (broadly speaking).
A few years ago, O’Reilly Media conducted research on data scientists:
Why do people use the term “data scientist” to describe all of these professionals?
[…]We think that terms like “data scientist,” “analytics,” and “big data” are the result of what one might call a “buzzword meat grinder.” The people doing this work used to come from more traditional and established fields: statistics, machine learning, databases, operations research, business intelligence, social or physical sciences, and more. All of those professions have clear expectations about what a practitioner is able to do (and not do), substantial communities, and well-defined educational and career paths, including specializations based on the intersection of available skill sets and market needs. This is not yet true of the new buzzwords. Instead, ambiguity reigns, leading to impaired communication (Grice, 1975) and failures to efficiently match talent to projects.
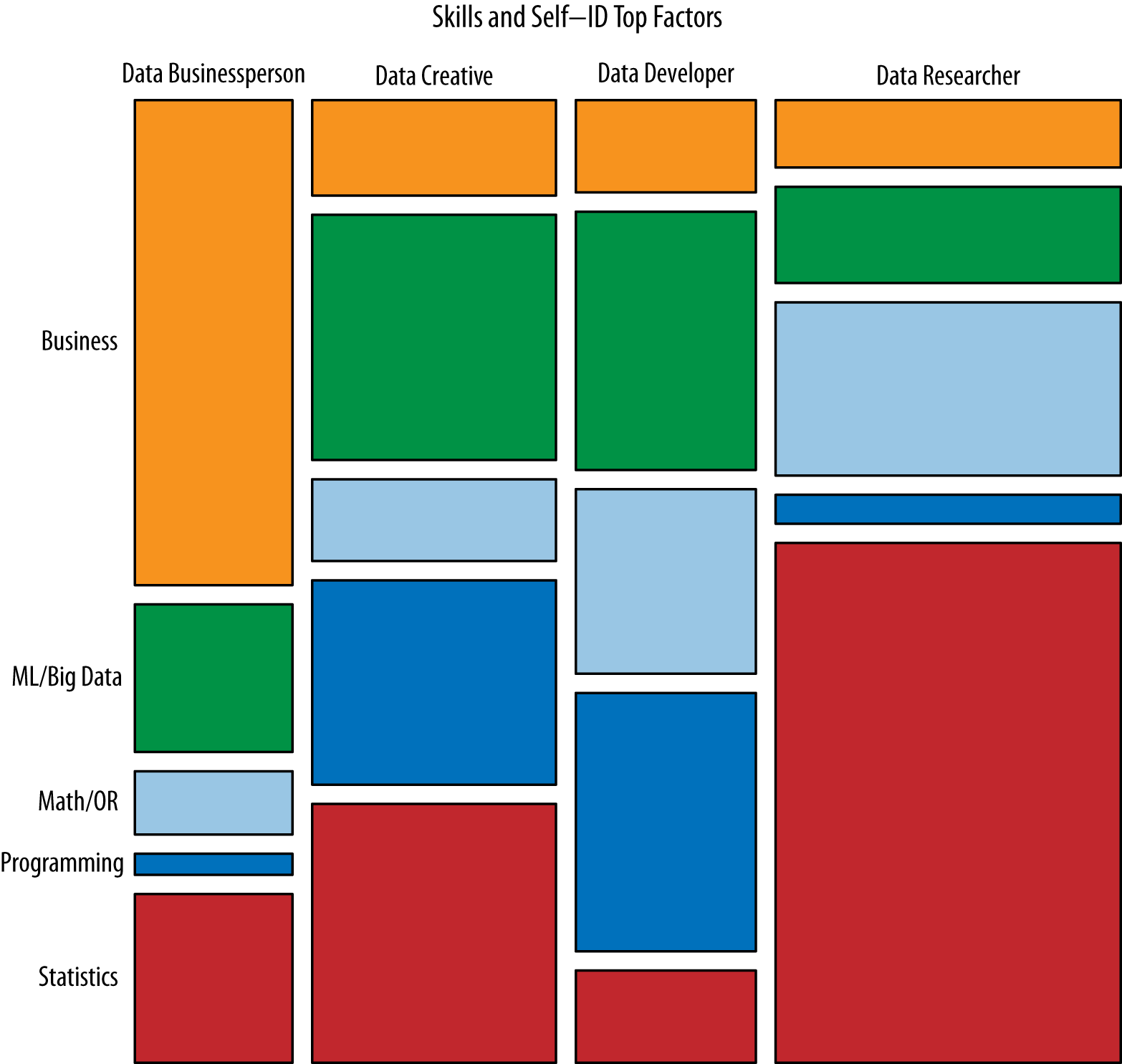
So… the ambiguity in understanding the meaning of data science stems from a failure to communicate? Classic movie references aside, the research from O’Reilly identified four main “clusters” of data scientists (and roles within said “clusters”):

Within these clusters fits some of the components described earlier, including two additional components: math/operations research (including things like algorithms and simulations) and business (including things like product development, management, and budgeting). The graphic below demonstrates the t-shaped-nature of data scientists — they have depth of expertise in one area and knowledge of other closely related areas. NOTE: ML is an acronym for machine learning.