Kubernetes is an open-source solution for automating deployment, scaling, and management of containerized applications. The business value provided by Kubernetes has been extending into the Serverless world as well. In general, Serverless <3 Kubernetes – with Kubernetes being the ideal infrastructure for running Serverless applications, because of a few key reasons:
- Kubernetes allows you to easily integrate different types of services on one cluster: From a developer’s standpoint, apps typically incorporate multiple types of components. Any complex solution will use long-lived services, short lived functions, and stateful services. Having all the options in one Kubernetes cluster lets you use the right tool for each job and still be able to easily integrate things together (whereas separate clusters will add both an operational and cost overhead.) FaaS works best in combination with other apps that runs natively on containers, such as microservices. For example, it may be the right fit for a small REST API, but it needs to work with other services to store State, or be suitable for event handlers based on triggers from storage, databases, and from Kubernetes itself. Kubernetes is a great platform for all these services to inter-operate on top of.
- Kubernetes is great for building on top of: it provides powerful orthogonal primitives and comprehensive APIs.
- You can benefit from the vibrant Kubernetes community: All the work being done in the community on areas such as persistent storage, networking, security, and more, ensures a mature and always up-to-date ecosystem of enhancements and related services. This allows Serverless to take advantage of things like Helm, Istio, ConfigMaps, Secrets, Persistent Volumes, and more.
- Kubernetes allows container-based applications to scale reliably and in a cost-effective manner – by clustering the containers within a container manager where they can be scheduled, orchestrated, and managed. This reduces operations cost considerably when compared to not using a cluster manager, and greatly increases the reliability of your service.
- Kubernetes’ scheduler and cluster management, service discovery, networking – are all required in a FaaS framework, and so by running Serverless on top of Kubernetes you avoid having to re-invent things, and can focus on the serverless functionality, leaving container orchestration functionality to Kubernetes.
- Being the standard, Kubernetes provides portability: Kubernetes has emerged as the de-facto standard for container orchestration across any kind of infrastructure. It thus ensures a consistent and native experience across cloud providers and across environments– from staging, to UAT, to Production. This enables true portability across any infrastructure – private or public. (Keep in mind, though, that as we’ve seen in Part 2 of this series, depending on your chosen Serverless framework, the application may need to be re-written if it is to be migrated to a different environment, not because of the Kubernetes backend, but because of the lock-in to integrated services provided by a specific cloud provider.)
Challenges with Kubernetes for Serverless applications:
While Kubernetes is a great underlying orchestration layer, it does require extensive set up and management overhead. There is still a significant amount of software “plumbing” to be built before deploying a Serverless application, even with Kubernetes. The code/function has to be written, the code has to deployed, containers need to be built and registered and then various configuration steps on Kubernetes (e.g. deploy, service, ingress, auto-scaling, logging) have to be carried out. Kubernetes is so robust and complex to manage, that it poses challenges to Ops in terms of the learning curve and the operational complexity – that hinder Serverless adoption, particularly for on-prem environments.
What is needed is a solution to help with reducing the time and effort spent on “plumbing” the Kubernetes infrastructure required for developing Serverless applications. What would be ideal for developers is to have a framework where functions are deployed instantly with one command. There should be no containers to build and no Docker registries or Kubernetes clusters to manage. Developers should focus only on “the code”, while the complex steps involved in packaging, deploying and managing applications are automated by the Serverless framework while being entirely native to Kubernetes.
Enters the open source Fission.
Fission is a Kubernetes-native, open-source framework for Serverless functions. With this free Function-as-a-Service (FaaS) solution, developers can easily code, deploy and operate Serverless applications that are production-ready from the get-go – without having to learn anything about Kubernetes. It also allows IT Ops to enable a Lambda-like experience (the Serverless service from AWS) in their own backyard – on any infrastructure, without risking lock-in or incurring additional cloud costs.
Built by Platform9 and other contributors in the Kubernetes community, fission focusses on developer productivity and accelerating time to value. Fission enables developers to write efficient, portable and high-performance Serverless applications that instantly run on any Kubernetes cluster – on-premises or in the cloud.
Serverless developer workflow:
- Developers easily write short-lived functions in any language
- Map them to triggers (message queues, timers, HTTP requests or other event triggers)
- The functions get deployed instantly to a Kubernetes cluster – no containers to build, no Docker registries to manage.
- When an event triggers the function, it’s instantiated along with the required underlying infrastructure.
- When the function has been idle for a (configurable) amount of time, resources are released.
Fission Architecture:
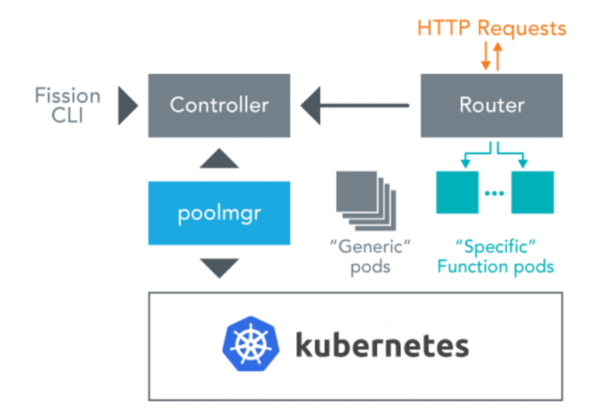
- Fission is designed as a set of microservices. A Controller keeps track of functions, HTTP routes, event triggers, and environment images. A Pool Manager (poolmgr) manages pools of idle environment containers, the loading of functions into these containers, and the killing of function instances when they’re idle. A Router receives HTTP requests and routes them to function instances, requesting an instance from the Pool Manager if necessary.
- The controller serves the Fission API. All the other components watch the Controller for updates. The Router is exposed as a Kubernetes Service of the LoadBalancer or NodePort type, depending on where the Kubernetes cluster is hosted.
When the router gets a request, it looks up a cache to see if this request already has a service it should be routed to. If not, it looks up the function to map the request to, and requests the poolmgr for an instance. The poolmgr has a pool of idle pods; it picks one, loads the function into it (by sending a request into a sidecar container in the pod), and returns the address of the pod to the router. The router proxies over the request to this pod. The pod is cached for subsequent requests, and if it’s been idle for a few minutes, it is killed. - Fission enables the easy deployment of Serverless functions on any Kubernetes cluster. Functions execute logically discrete, short-life tasks and can be used to deploy simple applications.
- Developing more complex applications leveraging the Serverless paradigm requires the composition of interacting Serverless functions. This has typically been a complex and time-consuming process. Fission Workflows enable the easy orchestration of a sequence of Serverless functions to create an application – which significantly accelerate the creation of Serverless apps.
- Workflows present an elegant way for integrating and composing serverless functions together by defining a sequence of tasks, decisions and loops. Functions can be composed either in sequence or in parallel. The output of a function can be sent to the inputs of another function, “if” statements, loops, and even functions that operate on other functions.
- Logging in Fission is supported via Fluentd and InfluxDB. Fission uses a Fluentd config that makes it source logs from any Fission pods and places them in a database – InfluxDB. Thanks to InfluxDB, users don’t need to install a whole ELK stack by default, and it is lightweight and simple to deploy. You can query logs from the Fission CLI, `fission function logs –name …`.
- Monitoring is supported via Prometheus, showing metrics for function call count, error count, call duration, (histogram) call overhead, response size, cold starts, function alive time, and more.
Reference Architectures for Common Types of Serverless Applications
At their core, Serverless functions are about running pure business logic or ‘functions’ inside a container. These functions could be anything that makes sense to a business application. Some common examples include:
- Payment Processing
- Alerting – sending an alert to a Security Ops Console
- Stream Processing – enriching a message with customer information
- Doing a credit check
- Submitting an insurance claim
Common use cases primed for Serverless functions include key industries, such as:
- Power & Utilities – where streaming data is intercepted and analyzed to perform demand forecasting, equipment reliability management, etc.
- Oil and Natural Gas Industry – Serverless is employed to perform log analytics to provide Single Views of Oil Wells
- Advertising – serving mobile & online users with instant & relevant offers based on their browsing history, location and buyer characteristics.
- Financial Services – such as banking and trading applications – where various facets of user data are populated in real-time in the customer portal.
- Healthcare – for example, population of health management data
Let us examine some design patterns for common industry use cases to see how Serverless can help you accelerate innovation and software delivery for key event-driven applications. We’ll be using the open-source Fission serverless framework for illustrating these architectures, as it is the most flexible and is not locked to a specific cloud provider or related services, so that your apps can run anywhere. You can swap Fission with any serverless/cloud offering of your choice, too!
Architecture #1: Internet of Things (IoT)
Typically in IoT – from industrial internet, to wearables, to smart cars – a set of autonomous physical devices such as sensors, actuators, smart appliances and wearables, collect various types of data and communicate with an application running in the datacenter (either cloud/on-premises) using an IP protocol. Commonly, a lot of the data is aggregated using a gateway and then sent into a platform that can analyze all these variables for various business insights (performance, trends, triggered events, and more.)
The overall flow in an IoT application can be orchestrated using Fissions:
- Data is aggregated using a Gateway and sent into to various message queues running on a cluster of Kafka servers running on Kubernetes managed pods
- Fission functions are invoked based on the overall pipeline flow:
- For a given file placed in a message queue, the contents of the file are passed into a Fission function that first normalizes it, extracts variables of interest and then sends the output into a NoSQL database or a file system.
- The second function will run in response to the normalized file being placed in the NoSQL database. It will read the contents of the file, perform computations as needed (based on the use case) and then invoke microservices that perform functionality such as sending the data into a Data Lake or a Data Mart for further analysis.
- Fission functions can be written for any kind of processing actions in the event stream. The FaaS scales up or down as needed in response to data volumes.
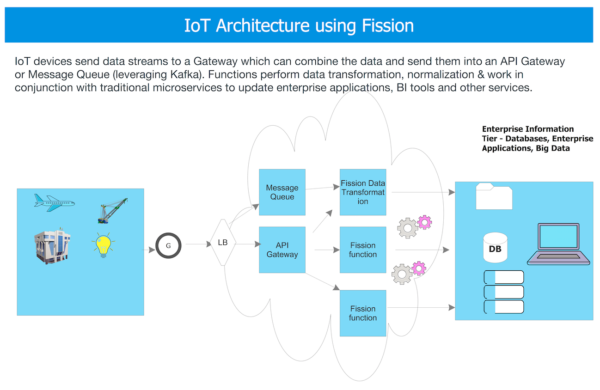
Architecture #2: Financial Services (Payments Processing, Risk Calculations, etc.)
In the financial services industry, critical tasks such as payments processing, compliance checks and risk metrics can be calculated in real time using a Fission-based Serverless architecture.
- The overall flow in a financial application can be orchestrated using Fission:Developer deploys Fission functions as a shared capability across several applications that are the frontend to a variety of payment processing gateways. These applications handle user authentication, registration & collection of payment related data. These systems also interface on the backend with a variety of databases that record transaction data.
- Fission functions are created to parse a given input data stream that has the following variables: user’s credit card data, location of the transaction, any other demographic information, etc.
- The first function can call a fraud detection API and based on the results of the check persist the data into an in memory data grid.
- The second set of functions is invoked when the check has either passed or failed. If the check has passed, the function approves the payment and sends the user a confirmation.
- If the payment is suspected to be fraudulent, another function is called which alerts a Fraud detection system at the backend.
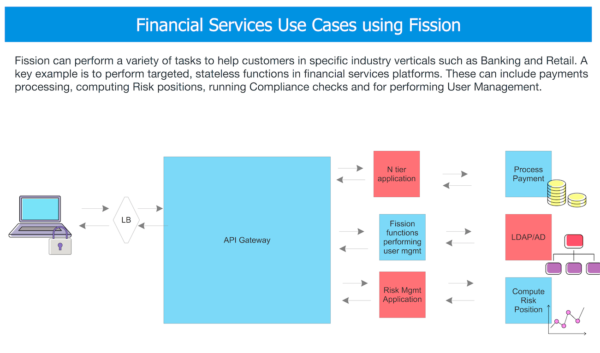
Architecture #3: Web Applications Augmentation
The vast majority of enterprise applications are ththree-tiereb applications. These do everything from onboarding new customers, to interfacing with various back-office functions performing a range of business tasks as well as technology tasks (such as backups, reporting, alerting, data enrichment.)
An emerging pattern is for Serverless Fission functions to handle these tasks without impacting the complicated development and deployment methodology of a monolithic n-tier application.
The overall flow in web applications augmentation can be orchestrated using Fission:
- Business users continue to interface with the (legacy) application, but can take advantage of the augmented functionality provided by Fission functions
- Functions are created for a range of compute and data processing tasks as depicted
- The main application triggers these functions as it opportunistically needs to do
- Dedicated functions perform the appropriate logic as depicted, and if needed “report back: to the application.
This could be seen as a way to gradually refactor or decompose/enhance existing legacy applications into microservices, or easily adding additional functionality that is not dependent on the development and release processes of the “mother ship.”
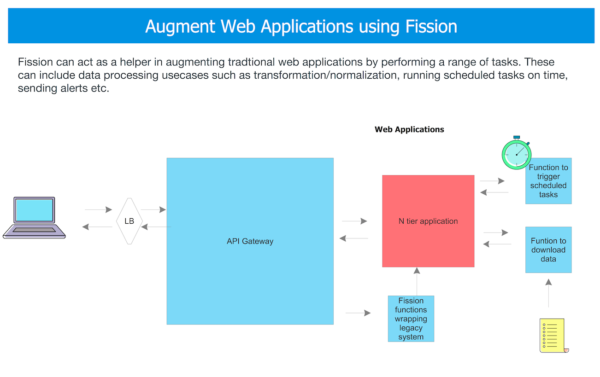
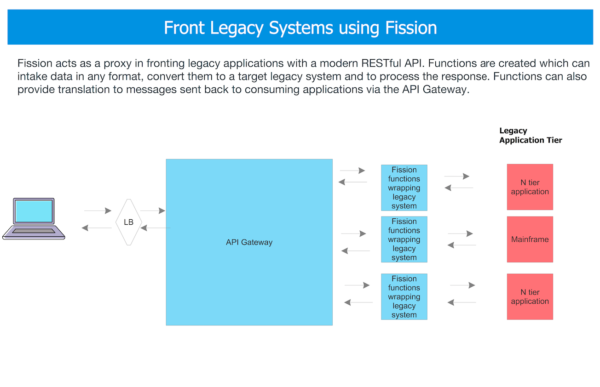
Architecture #4: Modernizing Legacy Systems
Legacy systems such as mainframes, N-tier applications are prevalent and deeply rooted in industries such as Banking, Insurance, Retail, and more. Oftentimes it is not possible to simply rip and replace these systems (due to complexity, business dependencies, time it would take to re-architect, as well as the fact that often these legacy systems still perform quite well and have mature usage patterns.) To ensure interoperability with modern interfaces, such as web services and mobile applications, Fission functions can provide standards-based API wrappers around these systems.
For instance:
- Requests are sent in to the API Gateway which performs basic transformation and invokes Fission functions as needed based on the endpoint being requested
- Functions take in the input data (e.g. JSON) and convert it to a format the end system can process and then calls the (legacy) business system
- Once the system responds, functions can take the response and convert it into a format the source system understands and then invoke the API Gateway with the appropriate response.
Architecture #5: Machine Learning and Deep Learning with Apache Spark
Across-industries, we see applications increasingly infusing business processes and big data with Machine Learning (ML) capabilities. From fraud detection, customer behavior and pipeline analysis, virtual reality, conversational interfaces, chatbots, consumption trends, video/facial recognition, and more — it seems that ML (and AI) is everywhere.
For most companies, ML and Predictive Analytics initiatives have typically been silo’d to a specific project within the organization. To realize the real value of ML, it’s advantageous for the data, learnings, algorithms and models to be shared across applications. Fission, in conjunction with technologies such as Apache Spark, enables you to provide the data of stream processing and trend predictions to be consumed by a variety of end users/applications.
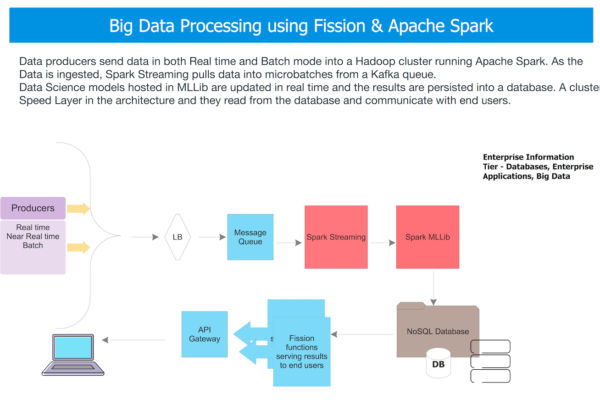
The overall flow in Machine Learning applications can be orchestrated using Fission and Apache Spark:
- Data from business operations is ingested in real-time into a cluster of Kafka-based message queues.
- Spark Streaming is used to ingest this data in micro batches, typically based on a time window. This data is stored into a data lake for batch analysis as well as sent into a Spark MlLib runtime where different predictive models are stored.
- These models are based on general purpose ML algorithms that run on Spark. These include both supervised and unsupervised algorithms – e.g. clustering, classification algorithms, etc.
- Once the results of the model are written into a NoSQL database or an in memory data grid, Fission functions are triggered.
- These functions do a range of business-critical functionality. For example: updating business analytics dashboards, sending real-time customer offers & alerting customer agents.
Conclusion
Serverless technology has immense industry mindshare and is emerging as the hottest trend after Kubernetes. However, as with other transformational technologies, significant concerns remain around lock-in, scalability and ecosystem integration. Open source Serverless solutions help industry verticals solve their pressing business challenges using a highly flexible, state of the art, and standards-based FaaS platform that can run anywhere- on premises and on any public cloud.